
Archetype AI Team
What Is Rule-Based Monitoring?
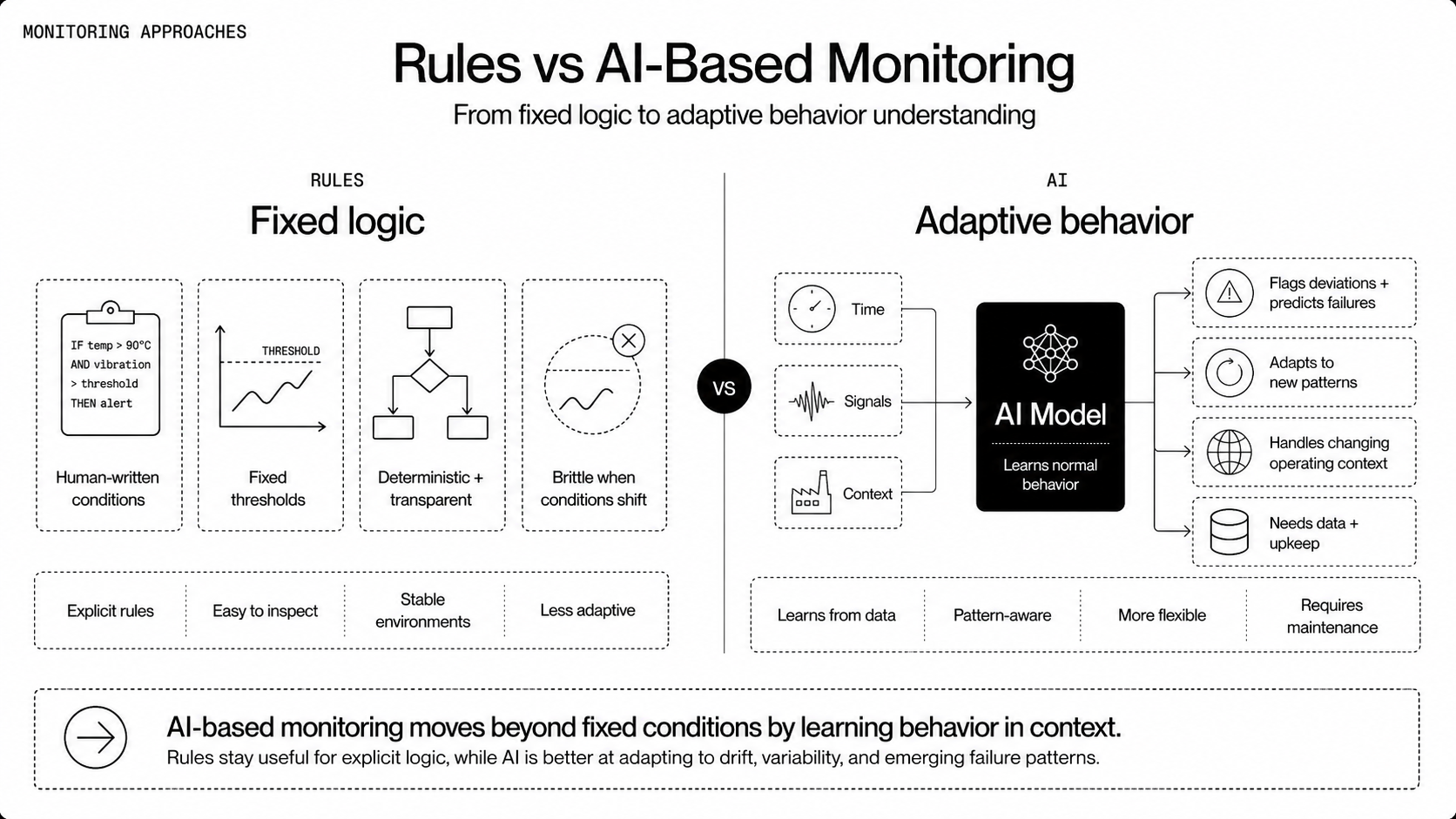
Rule-based monitoring uses explicit, human-written conditions to flag events or trigger actions. Rules codify what "bad" looks like in boolean logic, thresholds, or simple sequences. They were the default for decades because they're easy to understand and predictable.
How Rule Engines Work
A rule engine evaluates incoming signals against a library of conditions. Each rule contains a trigger, often a threshold, pattern, or time window, and an associated action. Engines run match-evaluate-act cycles, sometimes with rule chaining so one rule can enable or suppress others. The logic is deterministic, which makes behavior reproducible and debuggable.
Common Rule Types And Examples
- Threshold rules: CPU above 90 percent for five minutes triggers an alert.
- Pattern or signature rules: specific log patterns mark a security incident.
- Correlation rules: three failed logins plus a new IP within ten minutes equals a lockout.
- Stateful rules: a sensor change followed by a secondary sensor change within X minutes indicates a process fault.
- SLA and windowed rules: missed heartbeat for 30 seconds signals downtime.
Pros And Cons Of Rules
Pros: rules are transparent, fast to implement, and require little historical data. They map directly to business policies and are easy to audit.
Cons: they're brittle, they don't generalize to novel failures, and they generate noise when environments shift. As coverage grows, rules interact in unpredictable ways and maintenance becomes heavy.
Typical Maintenance And Scaling Costs
Every new asset or use case multiplies rule count and maintenance effort. SMEs must tune thresholds, resolve conflicts, and prune false positives. Alert fatigue raises human costs in triage and missed critical incidents. Operational overhead includes testing rule changes, version control, and tracking technical debt as the rule library grows.
What Is AI-Based Monitoring?
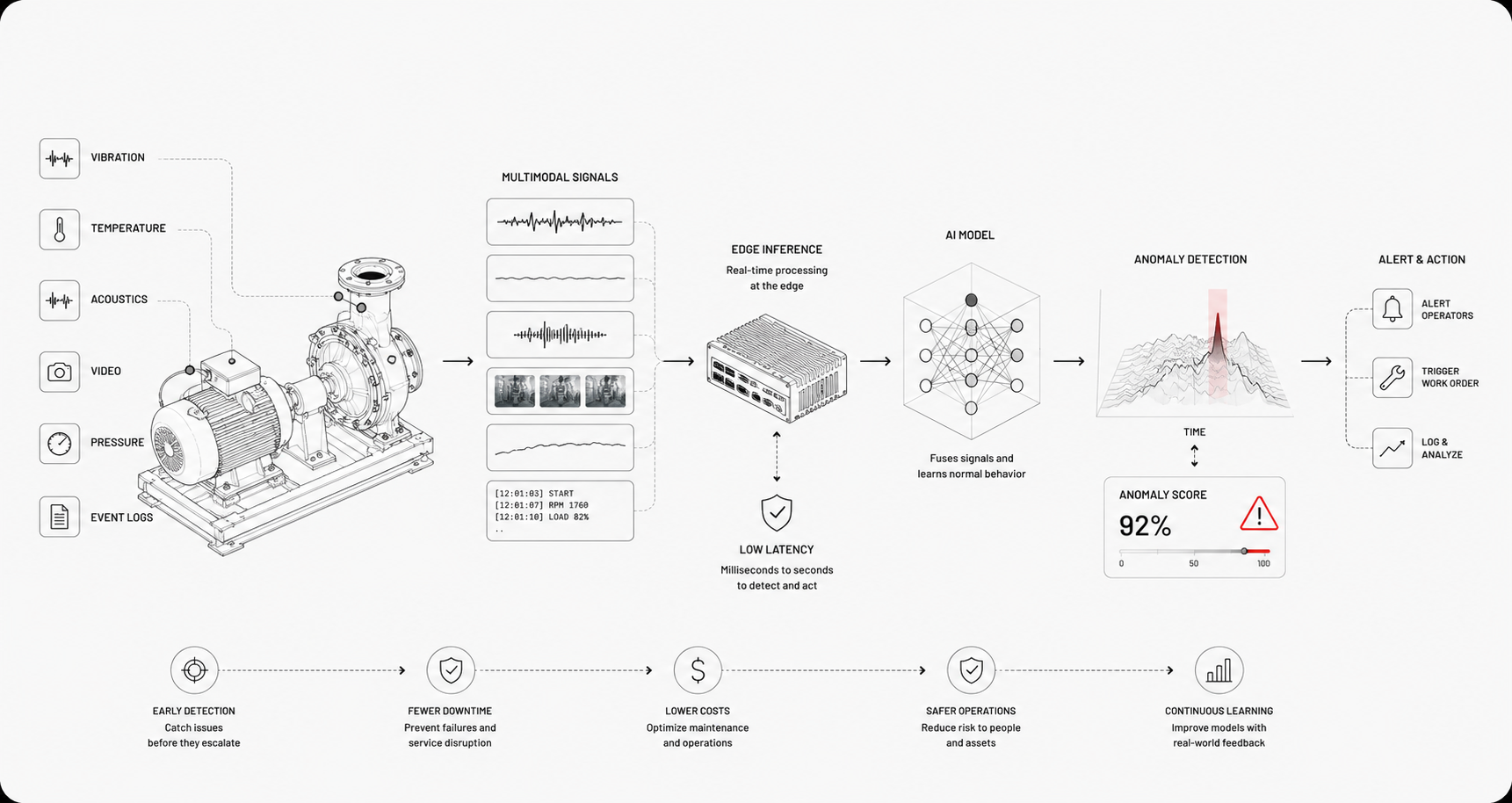
AI-based monitoring applies statistical learning and pattern recognition to detect anomalies, predict failures, and surface insights that rules miss. Instead of fixed thresholds, models learn typical behavior and flag deviations or predict future states.
Core AI Techniques Used
- Time-series forecasting to predict future readings.
- Unsupervised anomaly detection for unknown failures.
- Supervised classification when labeled incidents exist.
- Representation learning and sensor fusion to combine diverse signals.
- Transfer and self-supervised learning to leverage unlabeled data.
- Foundation models for physical signals, which offer reusable representations across domains.
Examples Of AI In Monitoring
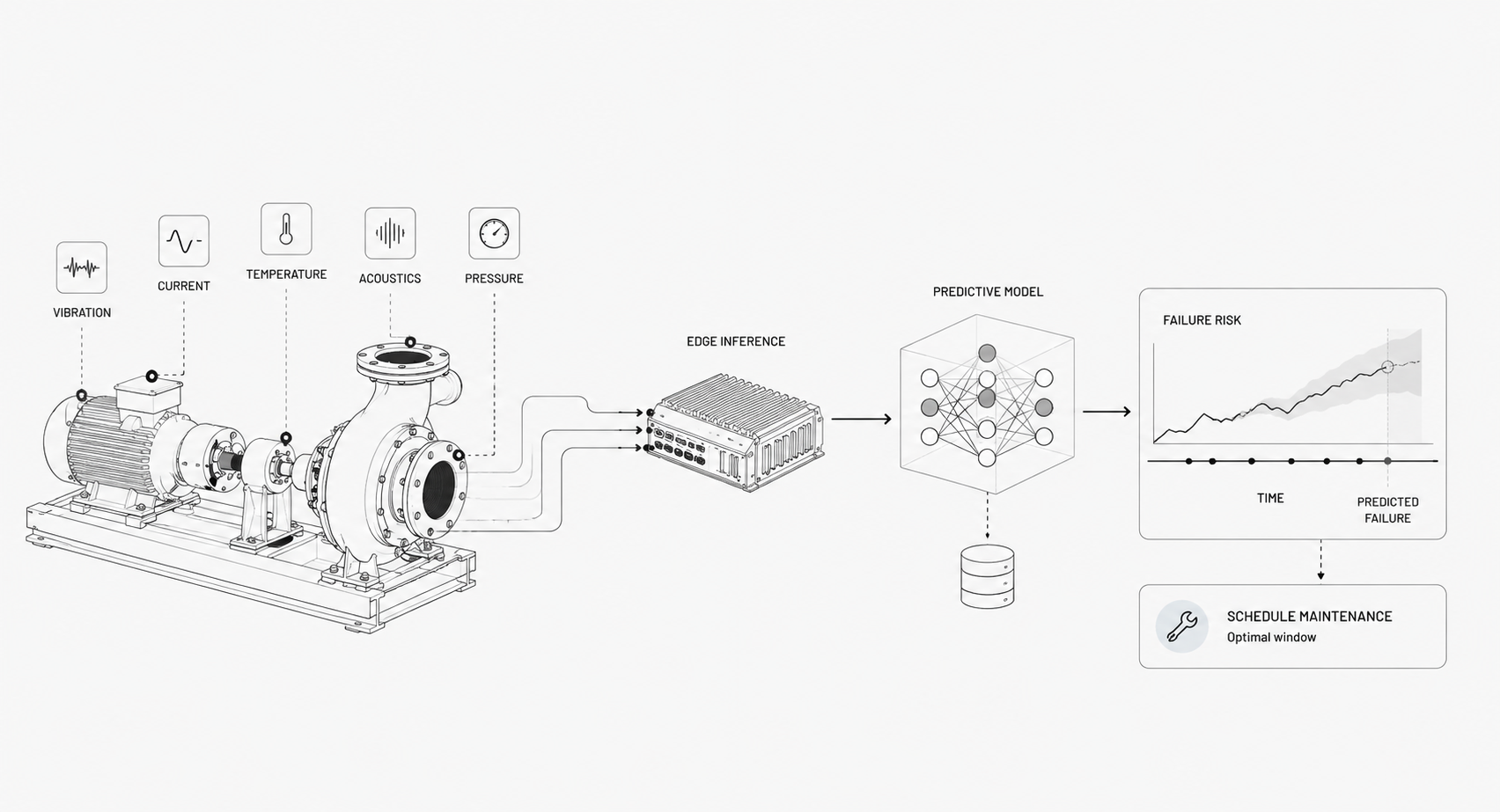
Predictive maintenance that forecasts bearing failure days in advance. Multimodal fusion where vibration, temperature, and audio together reveal equipment degradation — peer-reviewed industrial results show fused modalities outperform single-source models and stay accurate when one signal is noisy. Root cause ranking that points operators to the most likely failing subsystem.
Video analytics on construction sites that detect unsafe behavior before an incident. Foundation models like Newton, Archetype AI's model for the physical world, are the next step here: pretrained on hundreds of millions of sensor measurements, they fuse hundreds of sensor types in one shared representation and adapt to new equipment with a handful of examples rather than training from scratch.
Benefits And Limitations Of AI
Benefits: AI finds subtle correlations, adapts to new patterns, reduces false positives at scale, and enables predictive, not just reactive, workflows.
Limitations: models need data and care, they can be opaque, they drift as environments change, and they require MLOps to stay reliable. Compute and edge constraints also shape what’s feasible.
Data And Infrastructure Requirements
You need continuous ingestion, historical data retention, labeling pipelines for supervised tasks, and instrumentation for model feedback. Training needs compute and reproducible pipelines, inference needs low-latency serving, and production requires monitoring for model drift and performance. Governance, versioning, and annotation workflows are non negotiable if you want consistent outcomes.
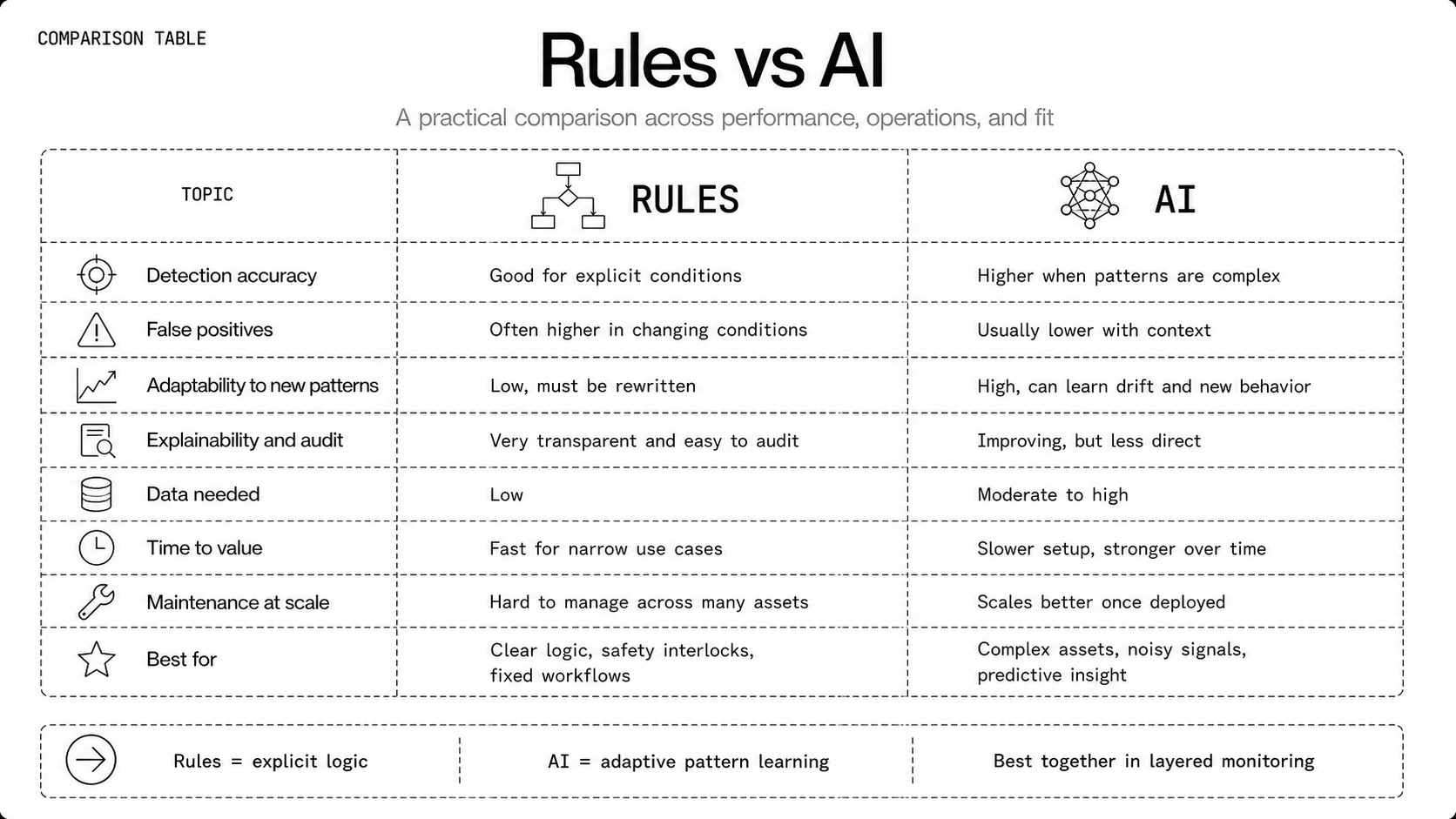
How Do AI And Rules Compare?
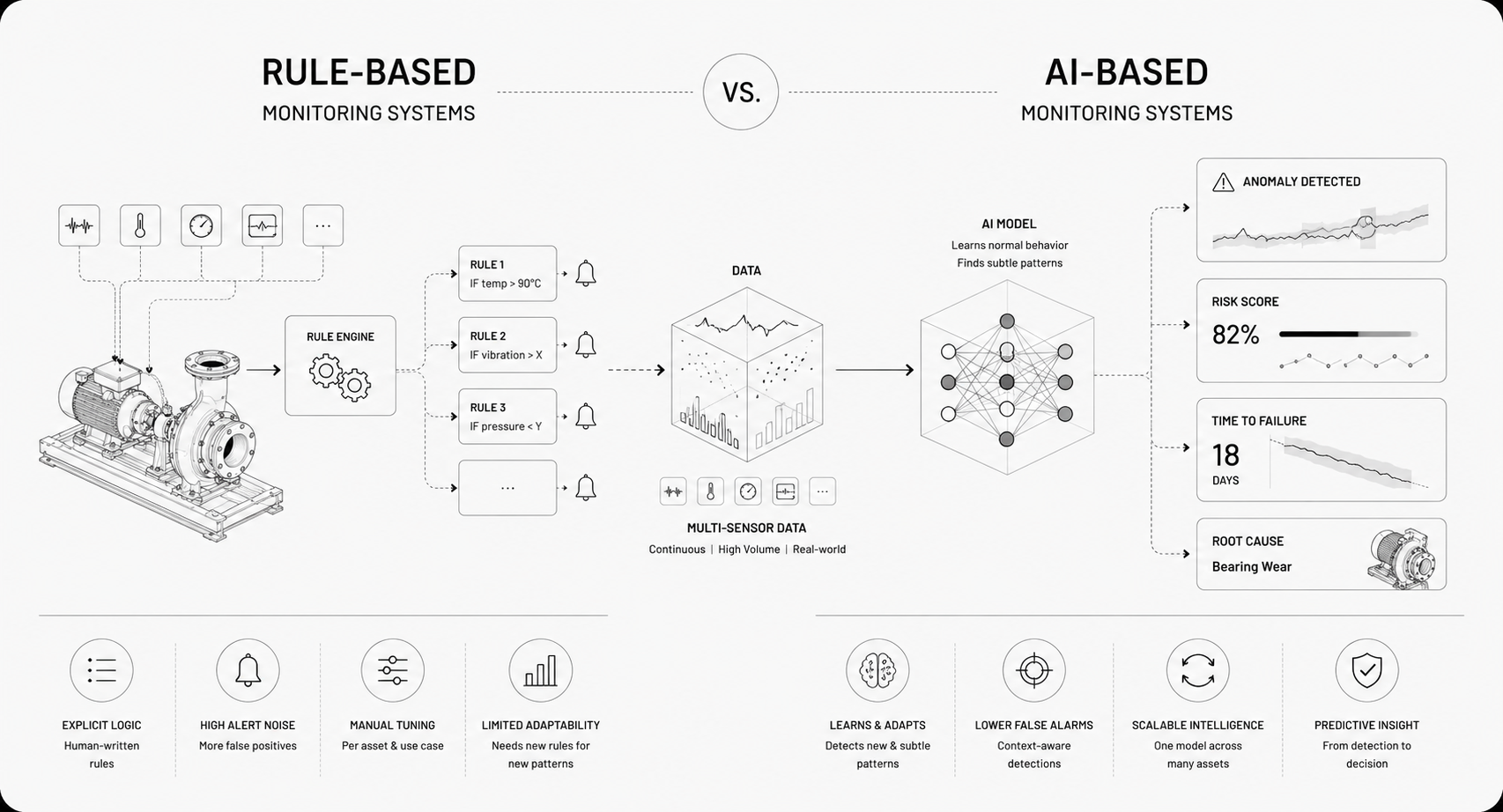
They solve similar problems from different angles. Rules encode certainty for known conditions, AI infers patterns from data and generalizes beyond explicit instructions. Both have trade offs across accuracy, adaptability, explainability, and cost.
Detection Accuracy And False Positives
Rules can be precise for well understood failure modes, but naive thresholds produce lots of false positives. AI tends to reduce noise by modeling context and variance, but it can miss extremely rare events if not trained on representative data.
Foundation models change that calculus: because Newton, Archetype AI's model for the physical world, learns the structure of normal operation across hundreds of sensor types, rare events fall outside the learned embedding geometry and reveal themselves without ever being explicitly labeled — exactly the regime where failures are too scarce to train on. The best outcomes often combine rules for known, high-risk checks and AI for ambiguous or high-volume signals.
Adaptability To New Threats Or Patterns
Rules are reactive, someone has to write the new rule when a new pattern appears. AI can surface novel anomalies and adapt through retraining or transfer learning, making it better at catching unknown-unknowns. Run out of the box across more than 40 sensors on complex wind turbines, Newton surfaced nine previously unknown failure patterns that even industry experts had not catalogued, an estimated $50 million-plus in annual downtime impact — the kind of unknown-unknown no hand-written rule would ever have been authored to catch.
The physical world generates trillions of signals, and AI is the only practical way to scale detection across that variety — Physical AI is becoming the foundation of industrial operations precisely because so much of that signal has gone unread.
Explainability And Auditability
Rules win for explainability, they're straightforward to audit and defend to regulators. AI needs tooling for attribution, counterfactuals, or surrogate models to reach the same level of auditability. In regulated environments, hybrid designs that use AI to detect and rules to validate often balance trust and power.
Cost, Time To Value, And Operational Overhead
Rules deliver fast time to value for focused problems, with low upfront cost but rising long-term maintenance. AI requires upfront investment in data, models, and MLOps, so time to value is longer.
At scale, AI amortizes costs and reduces manual toil. Because a foundation model ports across assets and sites, teams that build Physical-AI infrastructure today make each added use case cheaper than the last, so value scales faster than cost.
When Should You Use Rules Versus AI?
Choosing rules or AI isn't binary. Match tool to problem, volume, and risk appetite. Often they complement each other.
Use Cases Best Suited To Rules
Use rules when behavior is well defined, consequences are immediate, and transparency matters. Examples include compliance gates, hard safety cutoffs, SLA checks, and low-volume assets where building models isn’t justified. Rules are also ideal on constrained edge devices that can’t run ML.
Use Cases Best Suited To AI
Use AI when data volume, signal diversity, or novelty make rules impractical. Predictive maintenance across thousands of assets, cross-sensor failure detection, large-scale city infrastructure monitoring, and telecom root cause analysis are prime AI candidates. A
foundation model like Newton fits these cases because it fuses many sensor streams in one shared representation rather than scoring each in isolation — in a data center it combined temperature with video to tell a benign event, a person opening a door, apart from a true anomaly — and teams stand up new use cases with a handful of in-context examples instead of building a separate model per asset. If you need early warning or to uncover patterns humans can’t articulate, reach for AI.
Business Signals To Guide Your Choice
Pick AI when you have scale, historical data, or a high cost of missed detections. Pick rules when you need speed, airtight audit trails, or have limited data. If alert fatigue is eating ops time, that’s a signal AI might pay for itself. If you’re building long-lived physical monitoring, foundation models for sensor data are the next step — one model that ports across assets makes each new deployment cheaper than the last.
Examples By Industry And Volume
- Manufacturing: interlock safety remains rules, early detection of component wear across thousands of machines favors AI.
- Construction: single-site safety checks can use rules, multi-site sensor fusion for predictive safety calls for AI.
- Telecom: small cell thresholds run on rules, network-wide incident correlation benefits from AI.
- Smart cities: parking enforcement stays rule based, traffic flow prediction and incident forecasting need AI.
Pick the simplest tool that meets your reliability, cost, and compliance needs, then iterate toward AI when scale or complexity demands it.
How To Design A Hybrid Monitoring System
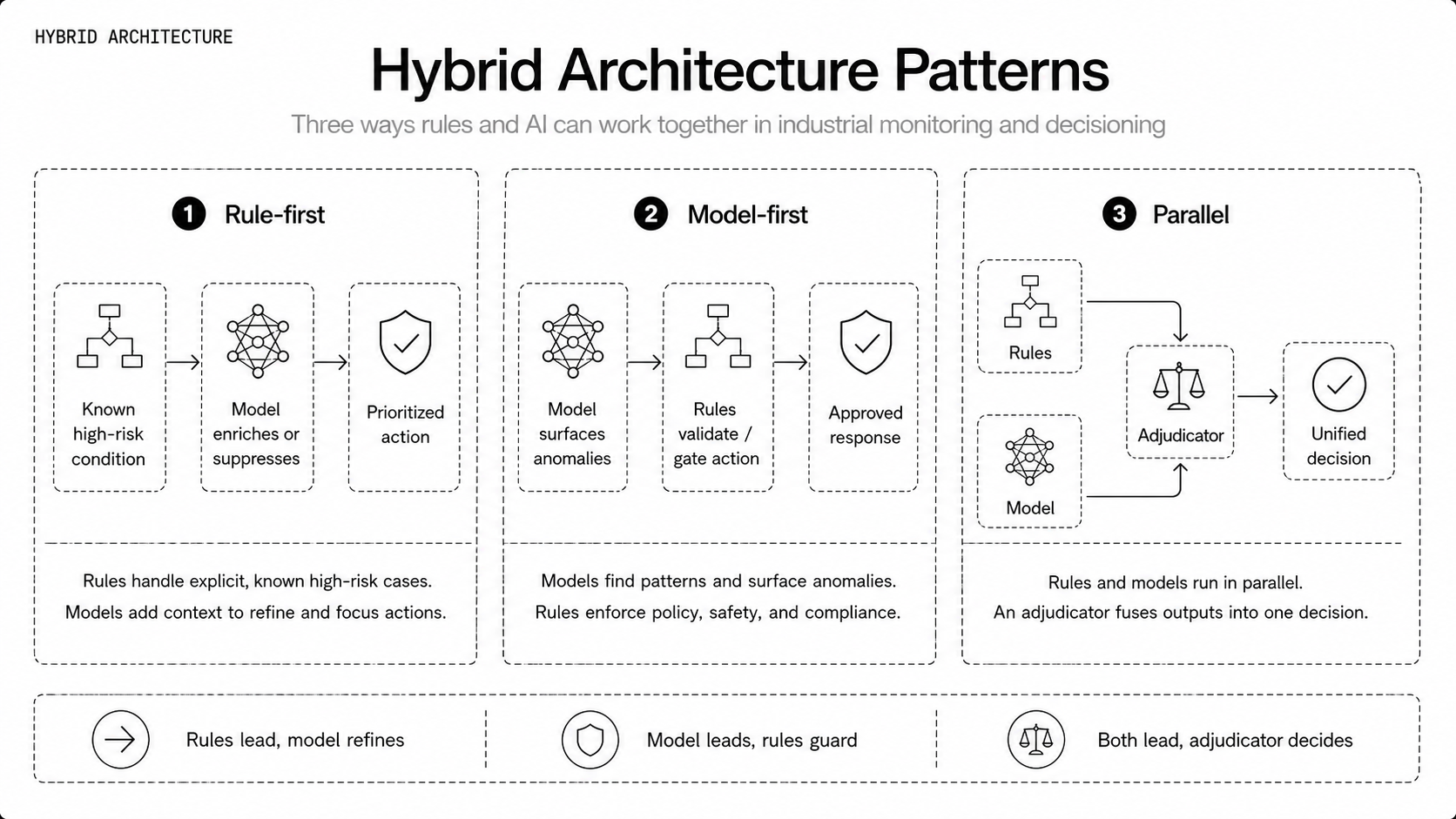
Hybrid Architecture Patterns
Hybrid systems mix deterministic rules with probabilistic models so each handles what it does best. Common patterns include rule-first, where rules catch known, high-risk conditions and models enrich or suppress those alerts; model-first, where ML surfaces anomalies and rules validate or gate automated actions; and parallel detection, where both run and an adjudicator fuses their outputs.
Architect these patterns with clear signal boundaries, deciding which features are preprocessed for rules and which feed model inputs. Expect to place some logic at the edge for latency or safety, and heavier fusion in the cloud where historical context lives. The physical world generates trillions of signals, so lean on representation learning to compress that variety into reusable features for both rules and models.
Orchestration Between Rules And Models
Orchestration is about routing, confidence, and contract. Define a runtime contract for each detector: input schema, expected latency, confidence score semantics, and actionability. Use confidence thresholds to decide when model results should override rules or when rules should suppress model alerts. Implement a lightweight adjudication layer that merges scores, tracks provenance, and exposes why a given path was taken. Keep orchestration stateless where possible, rely on a feature store for shared context, and make flows observable so operators can trace a decision from raw signal to action. If latency matters, build fast paths that favor deterministic rules, with models running asynchronously to enrich or re-score.
Prioritization And Escalation Workflows
Not every alert is equal, and triage must combine severity, confidence, and asset criticality. Map combined score to priority buckets that determine routing: auto-remediate, queue human review, or escalate to on-call. Suppression windows, deduplication, and correlation rules reduce noise by collapsing related alerts into a single incident. Embed uncertainty into the workflow, for example flag low-confidence, high-impact alerts for mandatory human approval. Capture operator decisions as labels to feed retraining and to refine prioritization heuristics. Design escalation with clear SLAs and playbooks so humans know when to act and when the system will act for them.
Governance, Testing, And Change Control
Hybrid systems need governance that spans code, rules, and models. Treat rule changes like code changes with versioning, CI tests, and peer review. Model updates need a parallel workflow: dataset provenance, training recipe, validation results, and deployment manifest. Use shadow and canary modes to test behavior against live traffic without changing controls. Maintain an audit trail that ties alerts to the rule or model version that produced them, plus the training data snapshot for models. Inject synthetic incidents to validate detection and ensure a rollback plan exists for both rules and model releases.
What Framework Should You Follow To Deploy?
Predeployment Checklist
Confirm data completeness, signal labeling, and schema stability before you go live. Verify instrumentation across the fleet and ensure telemetry reaches both rule engines and model pipelines. Define success metrics up front, like target precision at a given recall or reduction in mean time to detect. Ensure security and privacy controls are in place, with access controls for training data and inference endpoints. Prepare runbooks, rollback procedures, and stakeholder alignment on who approves changes.
Model And Rule Validation Steps
Validate rules with unit tests and regression suites that cover known edge cases and historical incidents. Validate models offline with backtests on held-out windows, measuring precision, recall, and business-facing KPIs like time-to-failure prediction accuracy.
Run models in shadow mode to compare against rules without impacting operators. Calibrate model confidences and translate them into operational actions through confusion-matrix driven thresholds. Finally, run adversarial and stress tests, including signal dropouts, to see how the hybrid responds when reality breaks the assumptions.
Continuous Learning And Feedback Loops
Design feedback loops that turn operator decisions into labeled examples at scale. Use active learning to surface uncertain cases for human review, prioritizing examples that will most improve model performance. Automate label ingestion, validation, and dataset versioning so retraining is reproducible. Monitor label drift and refresh cycles, and set policies for scheduled retraining versus trigger-based retraining when drift crosses a threshold. Closed-loop learning keeps models relevant while reducing manual cleanup over time.
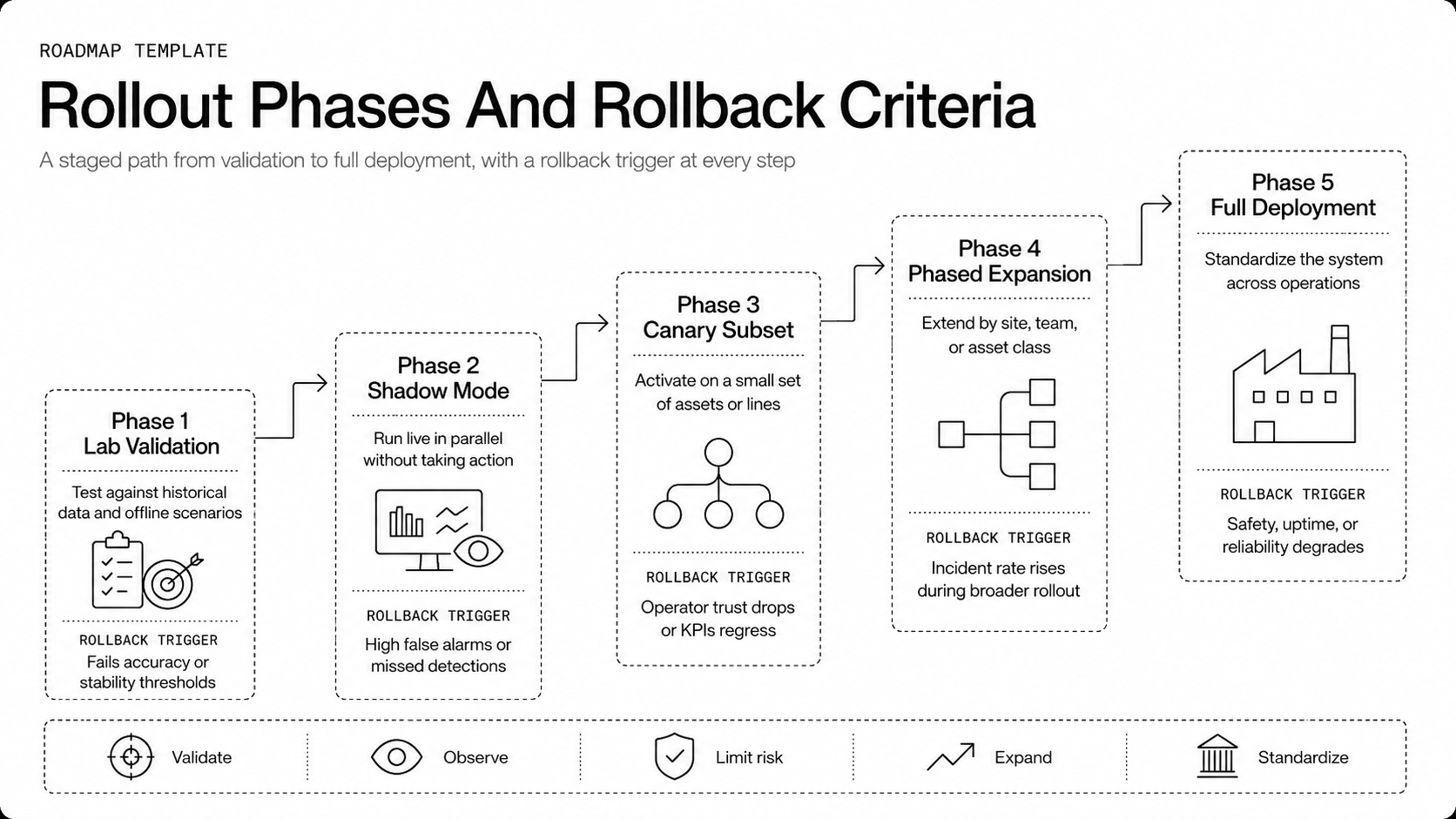
Rollout Phases And Rollback Criteria
Roll out in phases: lab validation, shadow mode, canary subset, phased expansion, full deployment. Define quantitative success criteria for each phase, such as alert reduction without loss of recall or stable latency under load. Establish rollback criteria tied to operational metrics, for example a spike in false positives, increased mean time to acknowledge, or a drop in specific detection rates. Automate safe rollbacks where possible, and require human approval for roll-forwards after a failed canary.
What Operational Metrics Should You Track?
Alerting And Accuracy Metrics To Monitor
Track precision, recall, false positive rate, and false negative rate, segmented by asset class and incident type. Measure alerts per asset per day to surface alert fatigue, and track precision at top-K to understand operator load. Tie detection metrics to business impact, like avoided downtime minutes or service level breaches prevented. Monitor how often rules and models agree, and use disagreement as a signal to investigate blind spots.
Performance And Latency Signals
Measure end-to-end time-to-detect, inference latency, pipeline processing time, and tail latencies. Track throughput and saturation points for both edge and cloud components. Latency matters for safety-critical systems, so instrument percentile metrics, not just averages. Correlate latency spikes with data volume, model version, and resource contention to pinpoint bottlenecks.
Cost, Resource, And Human Review Metrics
Capture compute cost per inference, storage and retention costs, and cost per alerted incident. Monitor human hours spent triaging, mean time to acknowledge, mean time to remediate, and percentage of alerts escalated to engineering. Combine these into a cost-of-error metric that quantifies the price of false positives and false negatives. Use these signals to justify investment in better models or rule consolidation.
Drift, Data Quality, And Explainability Indicators
Track feature distribution drift, label drift, schema changes, and missingness rates. Monitor model confidence distributions and calibration drift so you spot silent failures early. Measure explainability coverage, the share of alerts with a human-readable rationale or attribution. If explainability falls below a threshold, route those alerts to human review. These indicators protect against silent degradation and help meet audit requirements.
How To Handle Compliance And Explainability
Documenting Rules And Model Decisions
Record rule logic, versions, and intended intent in a searchable registry. For models, store training data snapshots, feature maps, hyperparameters, and validation reports alongside model artifacts. For each alert, attach the decision chain: inputs, rule matches, model outputs, scores, and the adjudication result. Make documentation accessible to auditors and ops so decisions can be traced from detection back to design.
Meeting Regulatory Expectations For Monitoring
Translate regulatory requirements into testable controls, for example proving a safety cutoff is always enforced by a rule, or that model-driven decisions have human oversight when required. Provide performance evidence over time, not just at deployment. Use conservative fail-safes where regulations demand deterministic behavior, and document when AI was used to augment rather than replace a compliance control.
Auditing, Logging, And Reporting Best Practices
Log raw inputs, intermediate features, model scores, rule firings, and final actions in tamper-evident stores. Keep retention aligned to regulatory windows and make logs queryable for post-incident review. Generate regular reports that aggregate detection performance, change history, and regression test results. Automate alerts for audit anomalies like unexpected rule changes or unauthorized model deployments.
Balancing Privacy With Detection Needs
Minimize data collection to what’s necessary for detection and retain sensitive signals in protected stores. Use aggregation, anonymization, and privacy-preserving techniques for model training where possible. When raw data is required for audits, gate access and log every access. Explainability should not expose private data; provide abstractions that justify decisions without leaking sensitive details.
What Common Mistakes Should You Avoid?
Overrelying On Static Rules Or Black Box Models
Relying only on rules makes you brittle, because every new asset or operating condition adds another rule to tune. Relying only on opaque models hands you scale, but little auditability, and blind spots when the world shifts. The sweet spot is a hybrid, where deterministic rules enforce safety and policy, and models surface subtle or high-volume patterns. Design for graceful disagreement, so when rules and models conflict, humans have a clear adjudication path.
Ignoring Data Quality And Labeling Issues
Bad labels and misaligned timestamps wreck both rules and models. Sensors drift, formats change, and missingness is common in the physical world, you must detect and remediate those problems early. Capture dataset provenance, sample selection logic, and label schemas, then monitor label drift like you monitor model drift. Invest a little in tooling for lightweight annotation and active learning, it pays back fast.
Poor Change Management And Review Processes
Treat rule edits and model releases the same way, with version control, peer review, and rollout gates. Skipping shadow tests or canaries means small changes can suddenly flood ops with noise. Keep rollback criteria explicit, log who changed what, and attach test artifacts to every change so auditors and engineers can replay behavior.
Underestimating Alert Fatigue And UX Needs
If operators get low-value alerts, they ignore the system, and risk rises. Too many alerts without context is a process failure, not just a detection failure. Design prioritization, deduplication, and clear justification into the UI, expose confidence scores, and let operators give quick feedback that becomes training labels. Remember, the system only pays back when humans can act on it reliably.
How To Measure ROI And Business Impact
Calculating Cost Per Alert And Savings
Start with a simple unit economics model: cost per alert equals average triage time times hourly rate, plus any automated remediation costs. Savings come from reduced false positives, faster mean time to detect, and avoided downtime minutes multiplied by revenue or penalty rates. Measure baseline costs, run the hybrid in shadow, then compute delta in total triage hours and outages avoided. Express ROI as payback period and percent reduction in operational spend.
KPIs For Fraud, Security, And Compliance Programs
Track detection precision and recall, time-to-detect, time-to-remediate, and false positive rate by alert class. Add business KPIs like incidents avoided, minutes of uptime preserved, fines averted, and SLA breach reduction. For compliance, measure audit coverage, decision traceability, and percent of model-driven actions with human approval. Tie these to dollar impact so you can compare model investment against other projects.
Case Examples Showing Measured Gains
A telecom pilot reduced noisy alarms by about 40 percent, cutting triage hours and enabling faster root cause hunts. A manufacturing fleet used predictive models to shift maintenance from reactive to scheduled repairs, lowering unplanned downtime by roughly 20 percent on the pilot line. A payments team combined rules with ML to drop false positive fraud holds by 30 percent while keeping true fraud detection steady. Use small, measurable pilots like these to build the business case before wide rollout.
What Real World Examples And Resources Exist?
Case Studies Across Finance, Security, And Ops
Finance uses hybrid stacks to catch novel fraud while keeping compliance rules for holds and reporting. Security teams blend signature rules for known threats with anomaly models for stealthy attacks. Operations and maintenance fuse vibration, temperature, and logs to predict bearing failure or unsafe site conditions. Construction, telecom, and smart cities already show how predictive physical intelligence moves organizations from reactive firefighting to planned prevention.
Open Source Projects And GitHub Repositories
Look for repositories focused on time-series anomaly detection, sensor fusion demos, lightweight feature stores, and model explainability for signals. Search for example pipelines that include ingestion, preprocessing, backtesting, and a shadow inference loop, they make good foundations for PoCs. Also seek datasets and notebooks that demonstrate transfer learning on physical signals, those accelerate experiments with small budgets.
How Implementations Have Evolved Since 2022
Teams moved from point solutions trained per use case to reusable representations and transfer learning for physical signals. Edge inference matured, letting low-latency checks run locally while heavier fusion lives in the cloud. MLOps shifted from ad hoc scripts to production pipelines that version data, models, and experiments. Foundation-model approaches now let teams adapt broad physical priors to specific assets, making pilots faster and cheaper.
Proofs Of Concept You Can Run Quickly
Pick 30 to 100 representative assets, run a simple anomaly detector in shadow for 4 to 8 weeks, and compare alerts to your rules. Inject synthetic faults or replay historical incidents to validate coverage. Run an A/B where one subset gets model-enriched alerts and the other stays rule-only, measure triage time and false positives. Keep scope tight, define success metrics up front, and capture operator feedback to feed retraining.
FAQs
What Are The Pros And Cons Of AI Versus Rules?
Rules are transparent, fast to implement, and safe for compliance, but they don’t generalize and require heavy maintenance. AI scales across diverse signals, finds subtle patterns, and enables prediction, but it needs data, governance, and ongoing ops. Use rules for deterministic safety controls and AI for scale and ambiguity, combine them where possible.
Can I Replace Rules Entirely With AI?
Rarely, not for safety or regulatory controls. Rules remain the right tool for hard cutoffs and auditable gates. AI can reduce rule surface area and automate many decisions, but a hybrid approach preserves safety, traceability, and operational continuity.
How Do I Start A Hybrid Project On A Small Budget?
Start with a single high-volume pain point, run a shadow model on a small fleet, and measure alert reduction and triage hours saved. Use open source components for feature extraction and backtesting. Convert operator decisions into labels during the pilot so the model improves without a big annotation budget.
Which Metrics Show Model Degradation?
Watch precision and recall by segment, calibration drift, the share of low-confidence predictions, and feature distribution drift. Also monitor disagreement rates with rules and rates of human overrides. When those change persistently, investigate data shifts and retrain or rollback.
Are There Ready Made GitHub Implementations?
Yes, but treat them as templates, not drop-in production systems. Look for end-to-end examples that include ingestion, preprocessing, backtest scripts, and a shadow mode. Validate them against your data and operational constraints before trusting them in the loop.
How Do Regulators View AI In Monitoring?
Regulators expect traceability, human oversight, and demonstrable controls. They accept AI as long as deterministic safeguards remain where required, and you can show performance over time. Keep audit logs, versioned training artifacts, and clear documentation so you can defend model-driven decisions.