Archetype AI Team
What Is AI For Industrial Asset Monitoring?
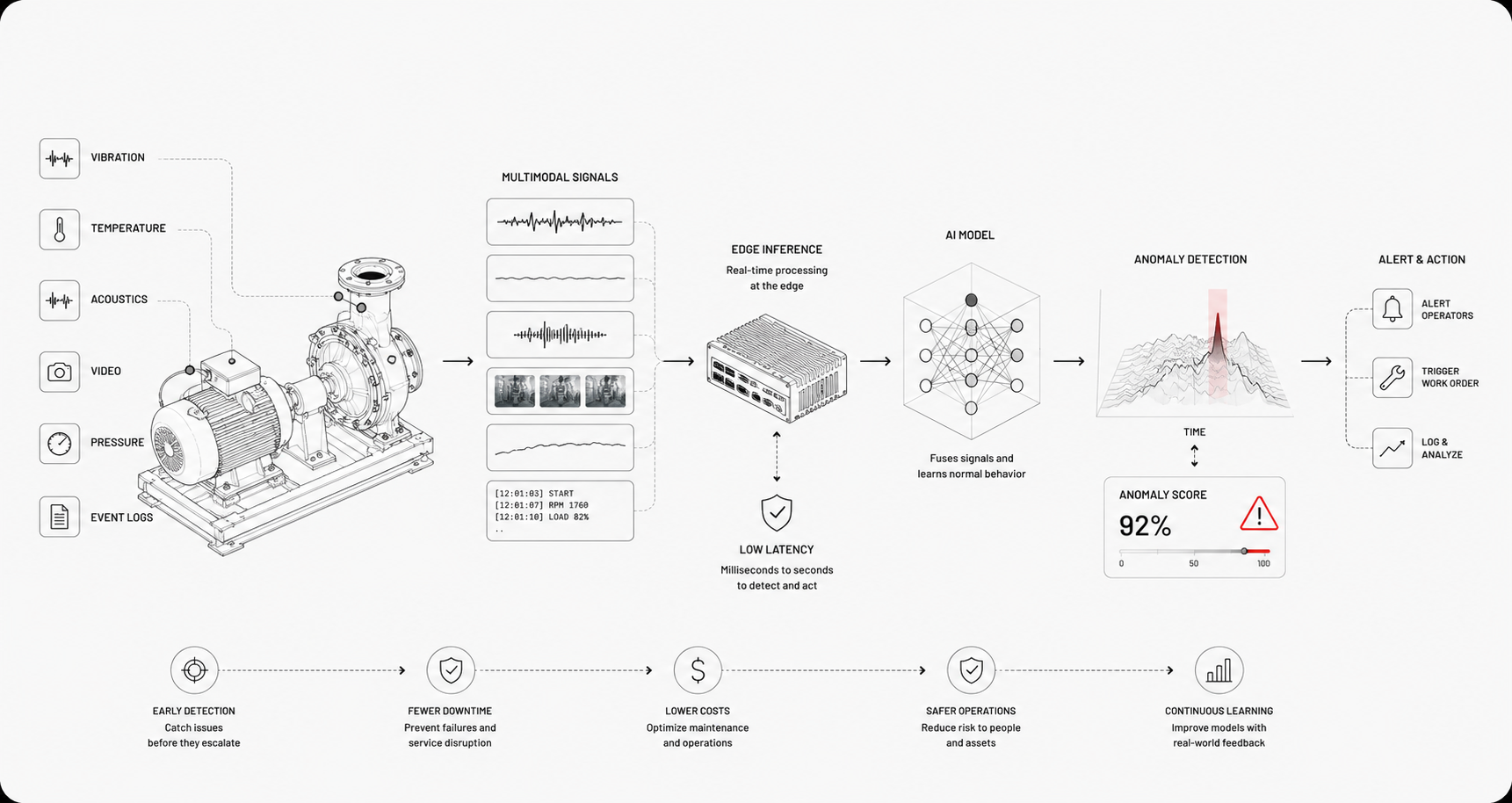
AI for industrial asset monitoring means using machine learning and related techniques to turn raw sensor signals into actionable insight about machines and infrastructure. It fuses continuous physical signals with context, historical records, and domain rules so teams can spot problems before they escalate and make smarter decisions about maintenance, operations, and safety. This is not just alerts on thresholds, it's intelligence that recognizes patterns, trajectories, and subtle precursors to failure.
How It Differs From Traditional Monitoring
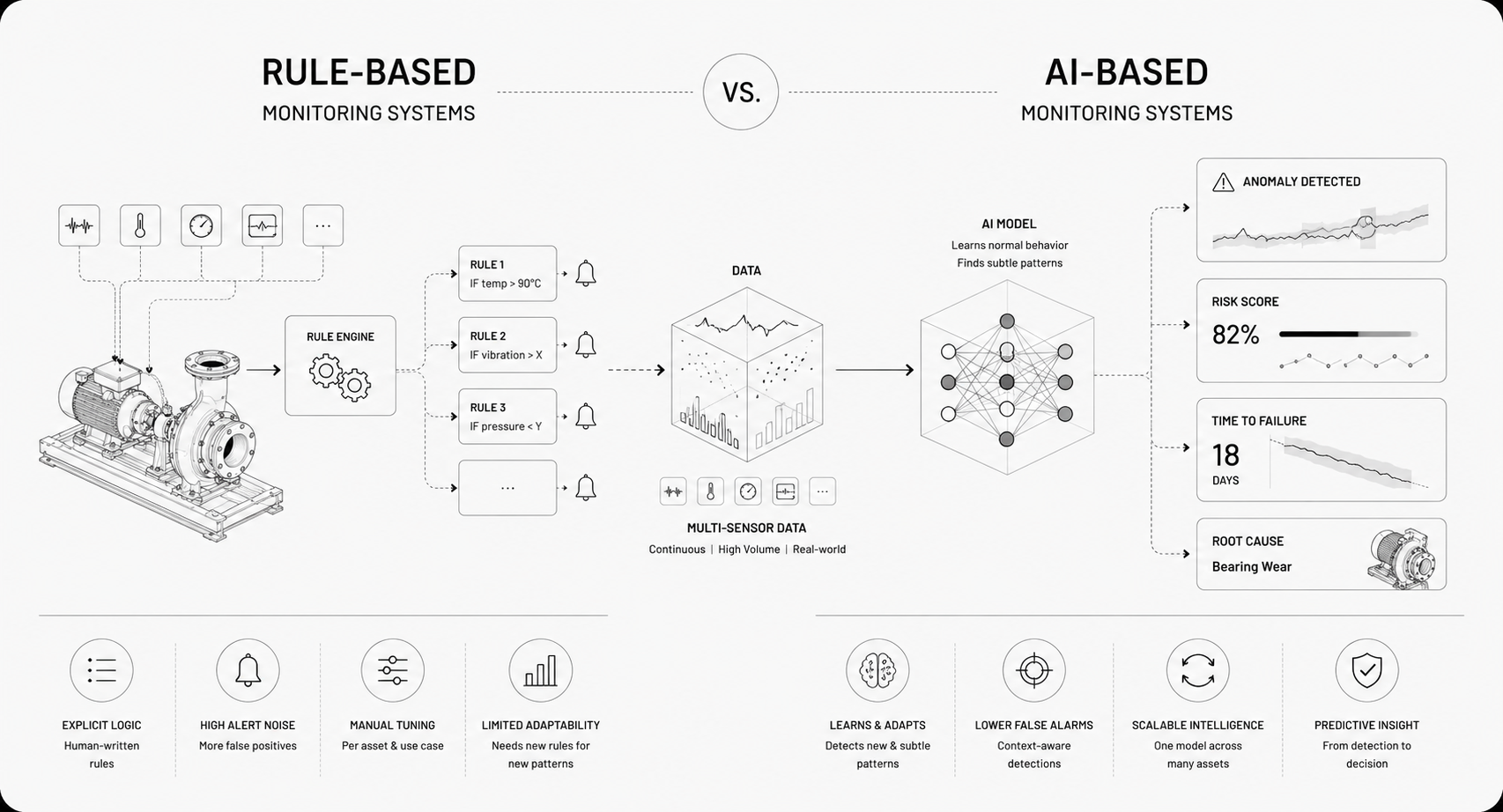
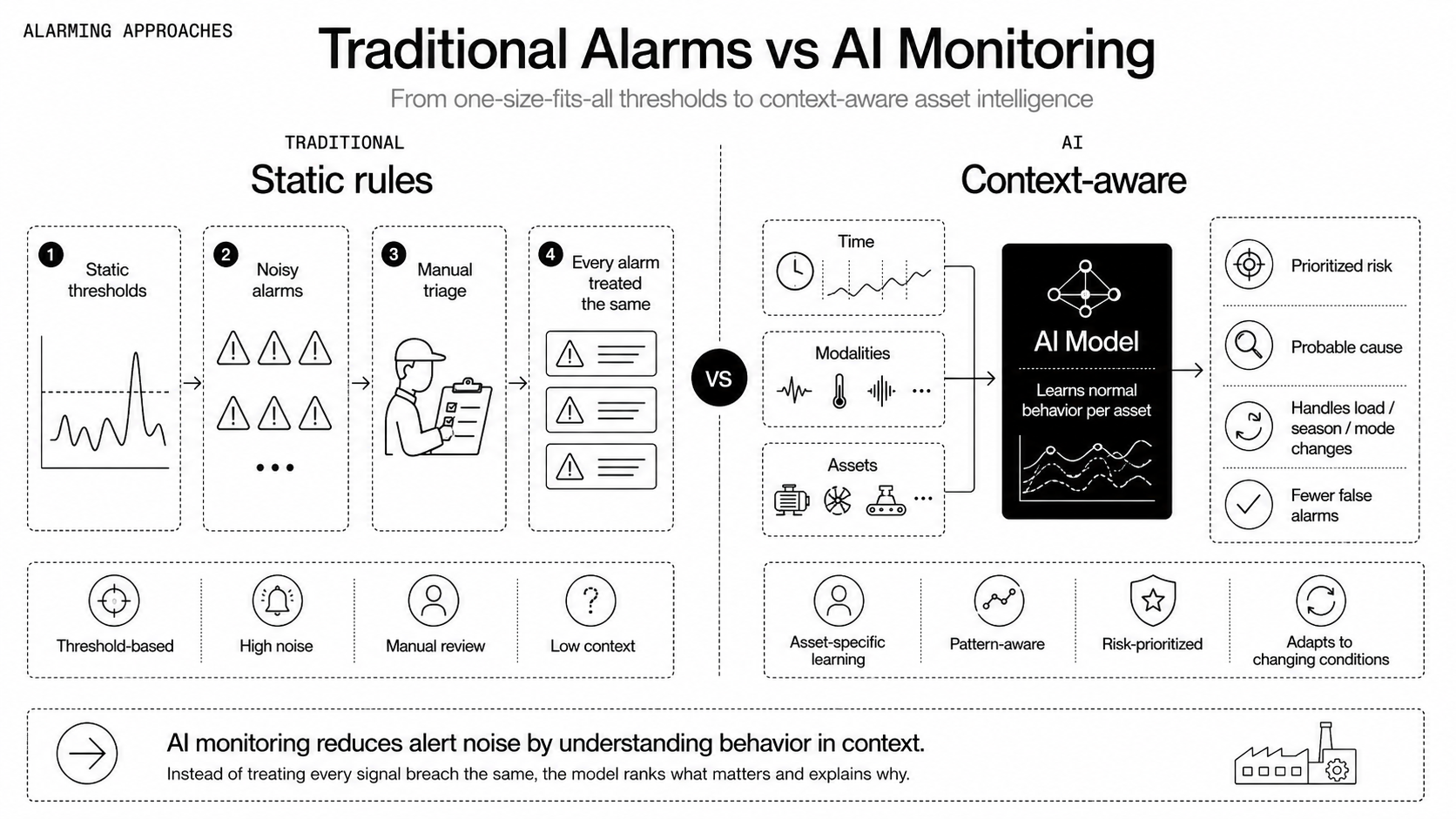
Traditional monitoring watches numbers against static thresholds and logs events. AI observes patterns across time, modalities, and assets, learning what "normal" looks like for each unit. Where conventional systems generate noise and manual triage, AI prioritizes risks and explains probable causes. It handles variability from changing loads, seasons, and operating modes, so you stop treating every alarm as the same problem.
Core Capabilities And Expected Outcomes
Core capabilities include anomaly detection, remaining useful life estimation, root cause inference, and automated diagnostics. Expect fewer unplanned outages, faster triage, more effective maintenance work orders, and improved asset utilization. On the strategic side, teams get fleet-level visibility, trend-based budgeting, and the ability to run simulated interventions before touching equipment.
Which Assets And Industries Benefit Most
Rotating equipment, power electronics, pumps, HVAC systems, telecom towers, heavy construction gear, and infrastructure assets like bridges and pipelines are prime candidates. Industries that move first are construction, telecom, and smart cities, but manufacturing, energy, mining, and transportation all benefit. Practically any environment that emits measurable physical signals can gain from Physical AI, because the underlying problem is universal, not niche.
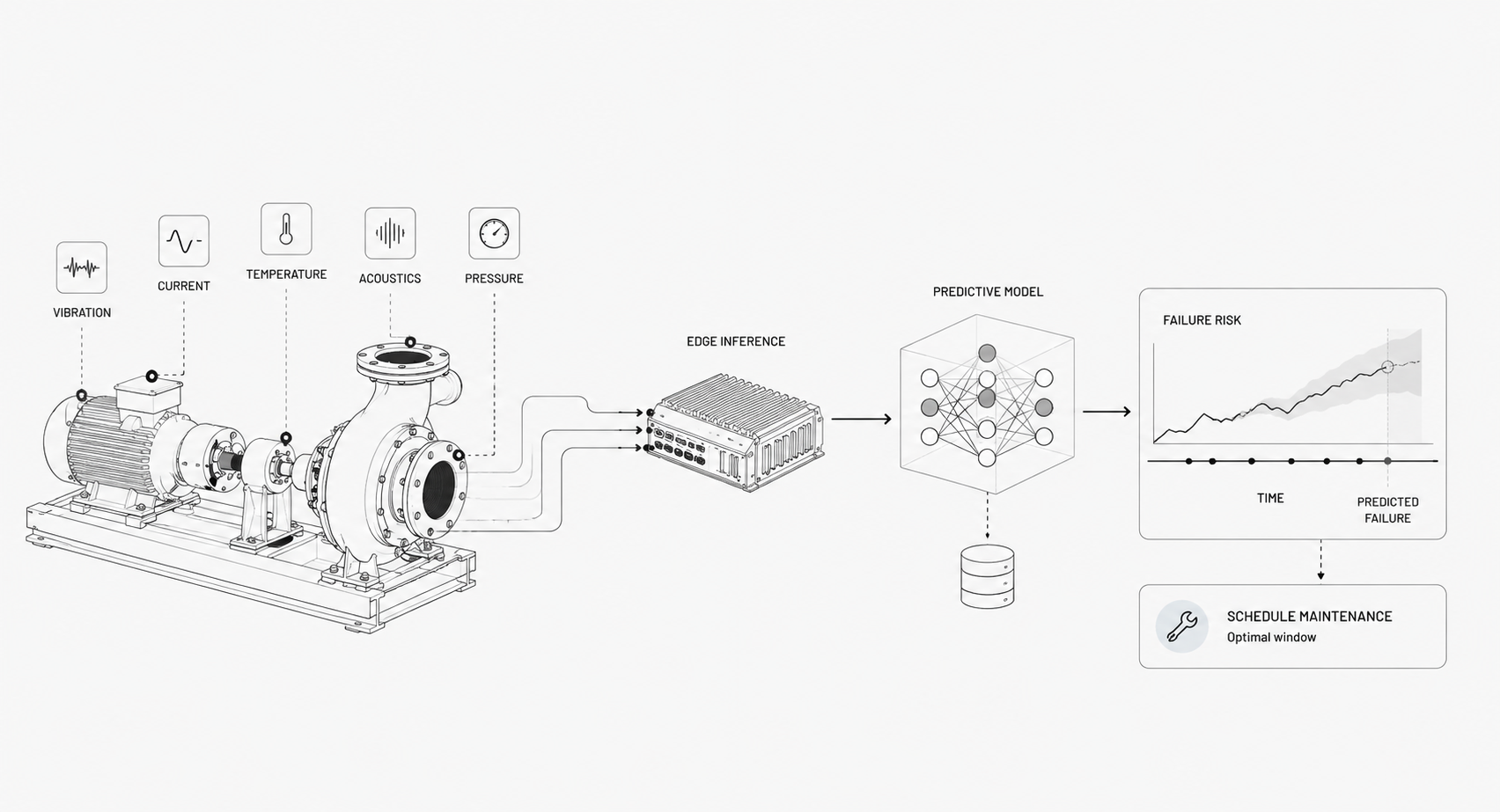
How AI Improves Asset Performance
AI turns noisy sensor streams into decisions that boost uptime, reduce cost, and make operations safer. The stakes are high: unplanned downtime now costs the world's 500 largest companies around $1.4 trillion a year, equivalent to 11% of their revenues, with an idle automotive line running to $2.3 million an hour. The shift is from reactive firefighting to predictive, measurable improvements.
Predicting Failures And Reducing Downtime
Predictive models detect precursors to mechanical wear, electrical faults, and system degradation days or weeks earlier than human operators. That lead time turns emergency repairs into scheduled interventions; Siemens reports that organizations running predictive maintenance see unplanned machine downtime fall by around 50% and forecasting accuracy improve by 85%. Fewer surprises mean higher availability and more predictable production. Fleet models also learn from failures across sites, so a rare failure pattern seen in one location improves detection everywhere.
Physical AI platforms are the next step here, because the hardest failures are the ones a single signal can't see. Run out of the box across 40+ sensors on complex wind turbines, Newton — Archetype's foundation model for Physical AI — surfaced nine previously unknown failure patterns that even industry experts had not catalogued, an estimated $50 million-plus in annual downtime impact. Because Newton fuses many sensor streams in one shared representation rather than scoring each in isolation, it catches multimodal failure modes a point solution would miss.
Optimizing Maintenance Schedules And Parts Use
AI recommends when to service assets based on actual condition, not fixed calendars. That slashes unnecessary parts replacements and labor, while ensuring critical components are changed before they cause downtime. The economics are well documented: Siemens finds predictive maintenance can cut maintenance costs by roughly 40% and pay back its investment within three months. Algorithms can prioritize work orders by risk and expected impact, aligning maintenance budgets with business outcomes rather than routine checklists.
Lowering Energy Use And Operating Costs
Signal-driven models identify inefficiencies like motor stall, suboptimal setpoints, or leaks that raise energy consumption. AI can suggest control adjustments, predict ideal operating windows, or flag devices for repair so energy savings are realized without manual tuning. Over time, these optimizations compound into meaningful cost reductions.
Improving Safety And Regulatory Compliance
Anomaly detection surfaces hazardous conditions such as overheating, gas leaks, or structural anomalies early. Automated records and explainable diagnostics simplify audits and incident investigations. That reduces liability, shortens response times, and helps keep operations within regulatory bounds.
Which Technologies Power Solutions
A stack of sensing, connectivity, signal processing, and modeling technologies makes modern industrial monitoring possible. Each layer matters, and the best solutions combine them rather than rely on one silver bullet.
Industrial Sensors And Signal Processing
Sensors translate physical phenomena into digital signals. Signal processing extracts the right features for AI models and reduces noise without throwing away rare failure signatures.
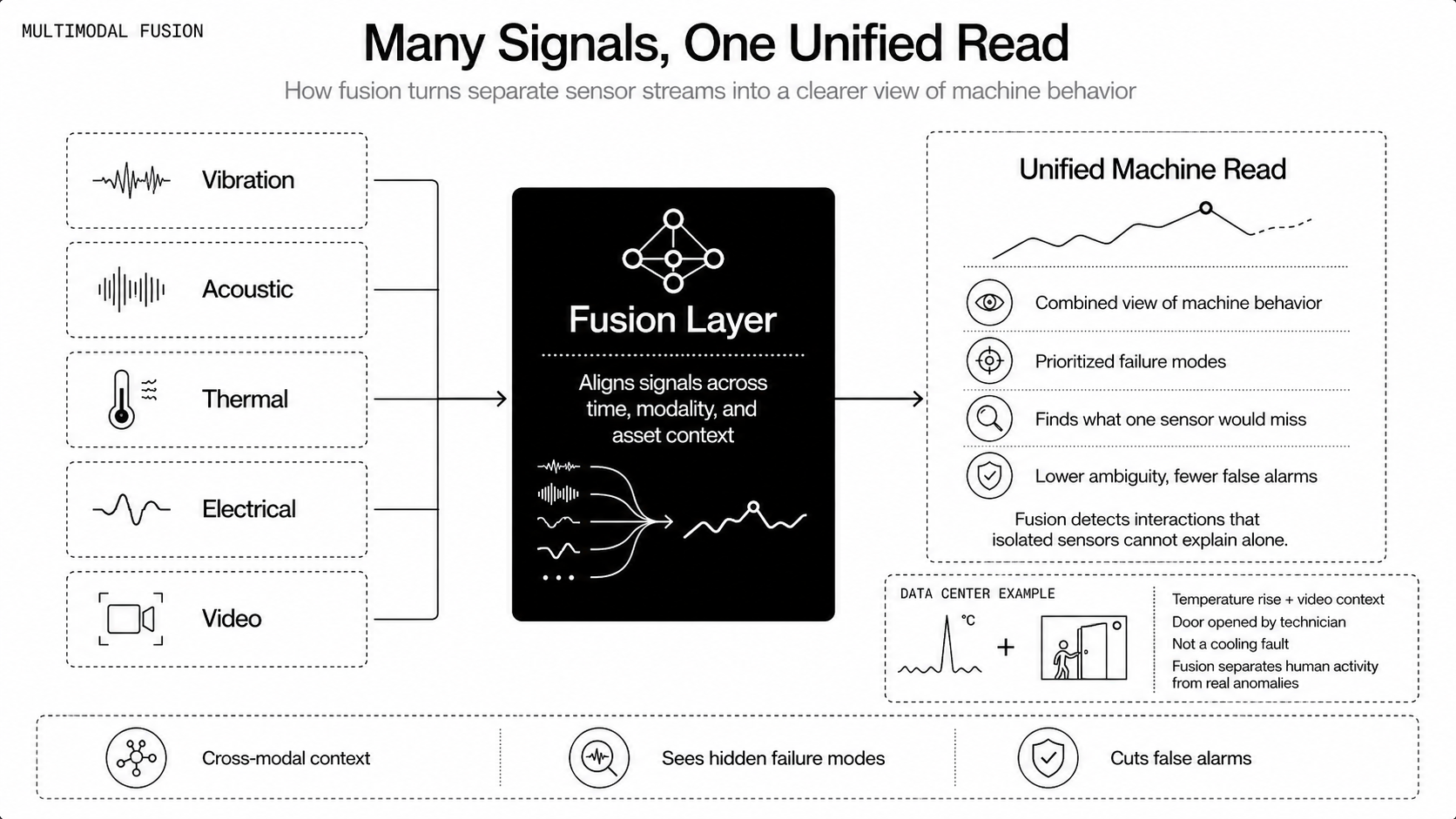
Vibration sensors and accelerometers reveal bearing faults, imbalance, and misalignment. Acoustic sensors detect impacts, air leaks, and valve chatter. Thermal cameras and RTDs show hotspots and heat-flow issues. Electrical measurements, like current, voltage, and harmonics, expose motor degradation, insulation failures, and power-quality problems. Combining these modalities uncovers failure modes that single-sensor systems miss.
Data Protocols And Connectivity Options
Reliable transport and context matter as much as the signal itself. Standards make integration and scale feasible.
OPC UA, MQTT, Modbus And SCADA Integration
OPC UA offers structured, secure industrial data modeling for plant-level systems. MQTT is lightweight and works well for distributed devices with intermittent connectivity. Modbus still dominates legacy device communications. SCADA systems remain the operational backbone at many sites, so tight, non-disruptive integration with existing SCADA is critical for practical deployments. A solution that supports these protocols reduces integration friction and accelerates rollout.
Machine Learning Types And Architectures
Supervised models classify known fault modes and estimate remaining useful life. Unsupervised and self-supervised methods surface novel anomalies without labeled failures. Time-series architectures like LSTM and transformers capture temporal dependencies. Graph neural networks model relationships among interconnected assets.
Foundation models for physical signals are the next step in this stack, mirroring the leap that NVIDIA and others have made with foundation models for Physical AI. Newton, Archetype's Physical AI foundation model, applies that idea to sensor data directly: trained self-supervised on nearly 600 million real-world sensor measurements, it generalizes across equipment types and domains without task-specific retraining. Instead of building a model for every asset from scratch, teams adapt it to new equipment with a handful of representative examples through in-context learning, collapsing months of custom ML work into days of configuration.
Computer Vision And Automated Inspection
Vision systems automate visual checks that used to need inspectors on site. Drones and fixed cameras perform corrosion detection, weld inspection, leak identification, and alignment checks. Combining optical, thermal, and multispectral imaging speeds inspection cycles and reduces human exposure to risky environments. Fusing vision with other signals is where Physical AI adds context: in a data center, Newton combined temperature with video to tell a benign event, a person opening a door, apart from a true anomaly, the kind of distinction a classifier looking at one stream cannot make.
Digital Twins And Simulation Models
Digital twins replicate asset behavior using physics-based equations augmented with data-driven corrections. They let you run what-if scenarios, test control changes offline, and validate anomaly hypotheses. Paired with live signals, digital twins combined with IoT and AI on the shop floor help separate sensor faults from genuine equipment issues and provide confidence in actionable recommendations.
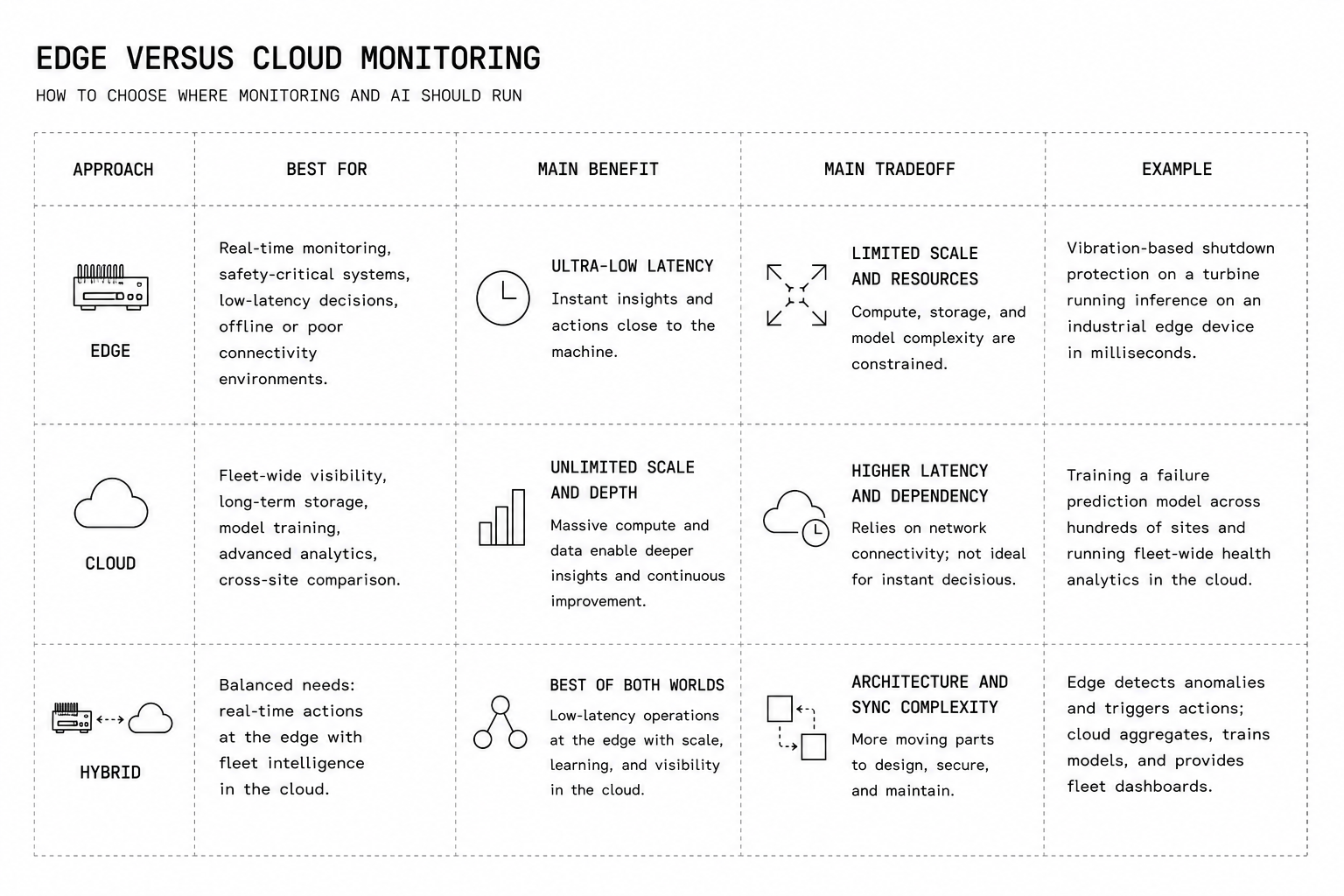
Edge Versus Cloud Monitoring
Choosing where to process data shapes latency, cost, and resilience. The right mix depends on use case, connectivity, and operational risk.
When To Process Data At The Edge
Put inference at the edge when you need sub-second responses, when bandwidth is limited, or when data must stay local for privacy or compliance. Edge processing reduces raw data egress, enables closed-loop control, and maintains operations during network outages. Peer-reviewed work shows that running anomaly detection on the edge cuts inference latency by an order of magnitude, and earlier detection translates directly into more time to mitigate a developing failure, which makes the edge the natural choice for safety-critical alarms and remote sites.
When To Rely On Cloud Analytics
Use the cloud for heavy model training, fleet-level aggregation, long-term trend analysis, and cross-site learning. Cloud platforms provide the scale and GPU horsepower required to build foundation models and retrain them on new failure modes. They also make it easier to deploy model updates across a wide fleet.
Designing A Hybrid Edge Cloud Architecture
Hybrid architectures run inference close to the asset and send summarized signals and contextual windows to the cloud for enrichment. The cloud trains and version-controls models, then ships optimized weights to edge nodes. Orchestration handles updates, model rollback, and data synchronization. This edge-cloud pattern balances responsiveness with centralized learning and governance.
Cost, Latency, And Reliability Tradeoffs
Edge reduces bandwidth and latency but increases per-site compute costs and maintenance. Cloud centralizes compute and lowers per-model cost at scale but adds latency and dependency on connectivity. Reliability depends on redundancy, local failover, and update practices. Choose the tradeoff that matches risk tolerance and operational constraints, and expect to iterate as use cases evolve.
Physical AI platforms are the next step in resolving this tradeoff, because the same model can run wherever the workload needs it. Newton deploys in the cloud, in a customer's own VPC, or as a self-contained container on existing edge gateways, down to hardware as modest as an Intel Atom, communicating over MQTT and OPC UA and connecting to existing SCADA historians without re-instrumenting the plant first. That portability echoes how most factory-floor physical AI now runs on lightweight edge compute, keeping data residency and operational control with the operator.
Key Use Cases With Real Examples
Predictive Maintenance In Manufacturing
Predictive maintenance replaces calendar-driven work with condition-driven actions. In a stamping line, vibration and motor current trends can reveal bearing wear and misalignment days before failure, letting planners schedule a single planned downtime rather than an emergency stop. On CNC spindles, tracking subtle changes in harmonic content and temperature drift yields remaining useful life estimates that cut unexpected tool changeovers and scrap. The trick is turning those traces into timely, prioritized work orders so maintenance teams stop firefighting.
Condition Monitoring For Rotating Equipment
Rotating machines live or die by vibration, acoustics, and rotor dynamics. Bearing defects show up as sidebands in the spectrum, imbalance raises RMS levels, and looseness changes phase relationships across sensors. Combine accelerometers, shaft tachometers, and current monitors and you can distinguish bearing failure from coupling issues without tearing down the machine. Fleet models learn rare failure signatures from one site and apply them across the fleet. The same multimodal approach extends to building systems: benchmarked against software purpose-built for HVAC, out-of-the-box Newton outperformed it, flagging faults like a stuck cooling valve, stuck damper, and filter restriction.
Vision Systems For Quality Inspection
Vision moves inspection from slow, subjective human checks to consistent, high-throughput systems. Fixed cameras and robots catch weld porosity, paint defects, and improper assembly using multispectral or thermal imaging layered with learned anomaly detectors. A drone-based visual sweep of a storage yard finds cracked panels and loose fasteners faster than manual rounds. When you combine vision with other signals, you reduce false positives and provide operators with exact images and timestamps for faster triage.
Remote Fleet And Asset Monitoring
Remote assets, from telecom towers to heavy haul trucks, benefit from lightweight edge models that summarize windows and ship only context-rich events. Telematics plus vibration and temperature streams let operators predict hydraulic leaks or drivetrain faults before route failure. In construction, equipment-level intelligence predicts idling inefficiency and hydraulic overheating, improving uptime and utilization across sites. The same approach scales to smart city infrastructure, where distributed anomaly detection preserves service while minimizing site visits.
Energy And Emissions Optimization
AI spots inefficiency patterns that humans miss. Compressor degradation, poorly sequenced chillers, or subtle valve leaks raise energy usage and emissions over time. Models that fuse electrical harmonics, flow rates, and thermal maps suggest control-set changes, flag components for repair, or trigger targeted audits. For emissions, acoustic and hyperspectral detection can find leaks that regulatory audits miss, letting teams prioritize fixes that reduce both cost and compliance risk.
Data Strategy And Quality Control
Choosing Sensors And Sampling Rates
Pick sensors to match the physics of the failure mode, not the vendor brochure. High-frequency vibration needs accelerometers sampled well above the highest fault frequency to avoid aliasing. Current and voltage require sufficient resolution to capture harmonics. Pressure and temperature trends need lower rates but high stability. Balance cost and coverage: more sensors and higher sampling improve detection but increase storage and edge compute. Design for upgradeability, because the data you need today often changes tomorrow.
Key Signals And Features To Track
Track raw waveforms when possible, but store derived features that compress information and speed inference. From vibration capture RMS, kurtosis, spectral peaks, envelope analysis, and cepstral coefficients. From electrical signals capture power factor, current harmonics, inrush patterns, and phase imbalance. For thermal and visual streams extract hotspots, texture metrics, and change-rate features. Contextual metadata, like operating mode, load, and maintenance history, is as important as sensor features for discriminating true faults.
Data Labeling, Augmentation, And Synthetic Data
Failures are rare, so labels are sparse and noisy. Use weak supervision, event-based labeling, and operator annotations tied to work orders. Augment data with time warping, noise injection, and domain-specific transforms that preserve failure physics.
Foundation models pretrained on physical signals change this calculus: because rare events fall outside the learned embedding geometry, a model like Newton can surface anomalies that were never explicitly labeled, which is exactly where failures are scarce. Where synthetic data is still needed, generate it from physics-based simulators and validate against real faults to avoid teaching artifacts.
Handling Missing, Noisy, And Legacy Data
Expect gaps, calibration drift, and inconsistent schemas. Time-synchronize sources with a single clock reference. Impute short gaps with interpolation, but flag longer outages and treat them differently in training. Use sensor fusion to overcome single-sensor noise, and apply robust feature extraction that resists spikes. For legacy systems, wrap gateways that normalize protocols and add minimal instrumentation rather than rip-and-replace. Maintain provenance so you always know which signals are original and which are reconstructed.
Storage, Retention, And Data Ownership
Store raw windows long enough to investigate incidents, but push summarized features for routine analytics to save cost. Define retention by regulatory needs, incident investigation windows, and model training requirements. Edge buffer policies should protect against connectivity loss and maintain secure handoff to the cloud. Clarify data ownership and access up front, between operations, IT, and legal, and enforce role-based access with logged lineage so models and auditors can trace decisions back to source signals.
How To Implement AI Step By Step
Selecting High Value Use Cases First
Start where failures are frequent, impact is high, and signals exist. Prioritize asset classes with repeatable failure modes and clear cost metrics, like downtime hours, parts cost, and safety exposure. Score use cases on detectability, ROI horizon, and operational readiness. Quick wins build trust, unlock budget, and create the training data that powers more ambitious, fleet-level projects.
Building The Data And Integration Layer
Implement time-synced ingestion pipelines, normalized schemas, and context enrichment from CMMS and PLCs. Capture raw signals in rolling windows and compute a standard feature set at the edge to reduce egress. Register asset metadata and create a canonical identifier system so models can learn across similar units. Provide APIs for both read and write so downstream systems can consume detections and push back annotations.
Running Effective Pilots And Proofs Of Concept
Run pilots that mirror production constraints, not contrived lab conditions. Define success metrics up front, including precision at a target recall, false alarm cost, and downstream impact on work orders. Use blind evaluation with historical incidents and holdout sites to avoid optimistic bias. Include end users in acceptance tests so the solution fits real workflows, not just dashboards.
Scaling From Pilot To Production
Automate deployment, monitoring, and rollback. Standardize model packaging, edge runtime, and telemetry so updates are repeatable. Build labeling pipelines and human-in-the-loop feedback to capture new failure modes. Expand incrementally by asset class and geography, and measure fleet-level uplift, not just pilot KPIs.
A single foundation model ports across assets and sites, extending a proven deployment from one machine to a fleet shifts from a multi-month project per asset toward roughly same-week configuration, so each new use case costs less than the last.
Vendor Evaluation And Procurement Criteria
Evaluate vendors on data-first integration, model lifecycle tooling, and ease of on-site deployment. Prefer vendors who support open formats and clear IP terms for models and data. Check whether the vendor has experience with similar physics and asset classes, and whether they provide tools for transfer learning rather than forcing full retrain from scratch.
Consider total cost of ownership, including edge hardware, ops support, and long-term model maintenance. If a vendor claims foundation models, ask how they adapt pretrained physical priors to your assets.
How To Operationalize Models At Scale
Deploying Models With MLOps Practices
Treat models like software components with CI/CD, versioning, and canary rollouts. Containerize inference, automate validation tests against held-out traces, and provide automated fallback to rule-based alerts when confidence is low. Orchestrate edge updates with secure over-the-air mechanisms and staged rollouts so a bad update never impacts the whole fleet. Instrument everything so you can trace alerts back to model version and input window.
Monitoring Drift And Managing Retraining
Detect both data drift and concept drift with statistical monitors on feature distributions and label quality. Trigger retraining when drift degrades key business metrics, and maintain a continuous labeling loop so newly observed faults are rapidly incorporated. Use validation on held-out sites and incremental fine-tuning to avoid catastrophic forgetting. Retraining cadence should match the pace of change in the physical system, not an arbitrary calendar.
Ensuring Explainability And Operator Trust
Operators need clear, actionable reasons for alerts. Provide concise explanations, like the features that triggered the alert, matching historical examples, and a confidence interval for recommended actions. Use surrogate rules or cause maps derived from model attributions to make outputs auditable. Trust grows when systems reduce false positives and when explanations map to workers' tacit knowledge.
Integrating With CMMS And Workflows
Connect alerts directly to CMMS so detections become prioritized work orders with suggested diagnostics, spare parts, and risk scores. Add feedback hooks so technicians can annotate outcomes, which feeds back into model training. Align AI-driven workflows with existing maintenance windows and vendor SLAs, so intelligence becomes an operational accelerator, not a parallel system.
Security, Compliance, And Industry Standards
OT Cybersecurity Controls And Best Practices
Industrial networks need segmentation, identity, and minimal trust, not an open pipe to cloud analytics. Start with network zoning, separate OT from IT with controlled gateways, and enforce least privilege for device identities. Apply secure boot and signed firmware on edge nodes, and require mutual TLS or equivalent for telemetry channels. Monitor for anomalous command patterns as well as sensor anomalies, because malicious actors often mimic sensor noise to hide activity. Regularly test incident playbooks with blue team exercises that include simulated sensor manipulation and recovery.
Safety, Regulatory, And Reporting Requirements
Monitoring systems change how incidents are detected and documented, which affects safety cases and regulatory filings. Map local reporting windows, notification thresholds, and record retention requirements before you act on alerts. Build audit trails that tie alerts to raw windows, model version, and operator decisions so regulators can reconstruct events. When models recommend actions that affect safety, require human-in-the-loop approval and store the decision rationale for compliance and post-incident review.
Relevant Standards And Protocols To Follow
Use standards the plant already trusts, and extend rather than replace them. Follow IEC 62443 for OT security practices, ISO 55000 for asset management alignment, and NERC CIP where applicable in power systems. Manage alerts against the ANSI/ISA-18.2 alarm management standard so rationalized, prioritized alarms reach operators instead of noise. For data interchange and modeling adopt OPC UA for structured telemetry, and use industry ontology standards when available so semantics travel with the signal. Standards reduce integration friction and make audits simpler, but interpret them in the context of operational risk, not as checkbox exercises.
Protecting Data And Intellectual Property
Sensor streams and derived models are strategic assets, treat them that way. Encrypt data in flight and at rest, enforce role-based access, and separate model weights from raw data in storage and deployment.
Define clear IP ownership for models trained on your fleet versus pre-trained foundation models, and include clauses for model export controls and derivative rights in supplier contracts. Protecting data also protects competitive advantage, because the operational intelligence a trained model extracts from your signals is hard for competitors to replicate.
Measuring Success And ROI
Key Performance Indicators To Track
Track both technical and business metrics, because they tell different stories. Technical KPIs: false positive rate, precision at target recall, mean time between false alerts, and model drift rate. B
usiness KPIs: reduction in unplanned downtime hours, percent of maintenance converted from reactive to planned, parts cost per asset, and technician touch time per incident. Add adoption metrics, like percent of alerts acted on within SLA, to measure operational trust.
ROI Calculation Framework And Payback Timeline
Build ROI from avoided costs and new value, not just license fees. Quantify avoided downtime, reduced spare part consumption, extended asset life, and labor savings from faster triage. Model conservative and optimistic scenarios, include one-time integration costs and ongoing model ops, and calculate payback using both cash flow and NPV for multi-year programs.
Expect faster payback on assets with frequent failures, and longer horizons for brownfield transformations that require instrumentation upgrades; for reference, Siemens reports predictive-maintenance deployments recouping their investment within three months on well-instrumented assets.
Tracking Model Performance And Alert Accuracy
Instrument models with continuous validation against labeled incidents and operator feedback. Use holdout sites for live A/B testing, and monitor precision, recall, and time-to-detection as rolling metrics. Track contextual failure modes, because a model that works at low load may fail under peak conditions. When alert accuracy degrades, surface root-cause diagnostics: data shift, sensor drift, or model aging, so you fix the right problem.
Reporting Results To Executives And Operators
Tailor reporting to the audience, keep both tactical and strategic views. Executives want dollarized impact, trend lines on downtime, and roadmap milestones. Operators need case-level evidence: the raw window, the model explanation, suggested diagnostics, and a simple feedback action. Combine a quarterly business scorecard with daily operational dashboards so wins are visible and trust compounds.
Common Pitfalls And How To Avoid Them
Avoiding Overfitting And False Positives
Overfitting happens when models memorize quirks of a pilot site, not generalizable physics. Use cross-site validation, augment with physics-based simulations, and prefer models that learn invariant features rather than site-specific noise.
Foundation models for physical signals help here: they reduce sample requirements and lower overfitting risk because they bring broader priors about how the physical world behaves, and Newton generalizes across machines, sensor types, and domains without per-asset labels, turning annotation work that once took months into configuration that can happen in days. Combat false positives by adding context filters, for example operating mode, maintenance overrides, and scheduled events. Set tolerances for acceptable false alarm rates linked to cost-of-response, then iterate until models reduce noise to a manageable level.
Managing Integration Complexity With Legacy Systems
Legacy PLCs and SCADA are unavoidable in many plants, but they need not block innovation. Use protocol gateways that normalize data and emit canonical asset identifiers, avoid invasive changes to controllers, and validate integrations in a staging environment that mirrors the plant. Document assumptions about timing and clock drift, because time misalignment creates phantom anomalies. Plan for incremental rollouts so you can validate behavior without risking operations.
Addressing Skills Gaps And Change Management
People matter more than models. Train operators on what alerts mean, how to act, and how to feed back outcomes. Create joint squads of operations, reliability, and data engineers to close the loop on incidents. Incentivize adoption with quick wins, like automated work orders that save an hour of triage.
Hire for signal engineering skills, or partner with teams experienced in Physical AI, because foundation models change the skill mix from pure data science to domain-aware engineering. Remember too that having lots of sensor data is not the same as having AI-ready data: a historian full of logs is not a pipeline a model can consume, so the shift to Physical AI is a mindset change across the organization, not just a technology upgrade.
Identifying Hidden Costs And Vendor Risks
Compute on edge, data egress, maintenance of custom connectors, and labeling labor add up fast. Vendor claims of turnkey deployment often hide significant integration and ops work. Negotiate clear SLAs for model performance, uptime, and security, and require transparency over model provenance if you rely on pre-trained physical priors. Avoid single-vendor lock-in by insisting on open export formats for models and data, so your Physical AI infrastructure remains portable.
FAQs
What Is AI In Asset Monitoring?
AI in asset monitoring means models that turn raw, continuous sensor signals into prioritized, explainable actions. It goes beyond threshold alerts by learning normal behavior for each asset, spotting subtle precursors to failure, and estimating remaining useful life.
Think of it as bringing the same leap LLMs gave text to the physical world, using multimodal signals like vibration, current, acoustics, and vision. The result is less firefighting, faster triage, and decisions informed by patterns across a fleet, not isolated readings.
How Long Does Implementation Take?
Expect a staged timeline, not a single number. A narrow pilot on well-instrumented assets can deliver meaningful alerts in 8 to 12 weeks. Expanding that pilot to a resilient, fleet-scale deployment usually takes 6 to 18 months, depending on instrumentation, integrations with CMMS and SCADA, and change management.
Foundation-model approaches shorten custom model development, since many use cases run out of the box with a few in-context examples, but you still need time for validation and operator adoption. Plan for continuous improvement after launch, because model ops and feedback loops never really stop.
Can AI Work With Legacy Equipment?
Yes, almost always. Use protocol gateways to normalize Modbus, OPC UA, and SCADA outputs, add non-invasive sensors where needed, and run edge summarization so you don't overload networks.
A foundation model that connects to existing SCADA historians and edge gateways through pre-built connectors avoids the need to re-instrument or standardize hardware first. The practical route is incremental: instrument the highest-value assets first, wrap legacy endpoints with gateways, and avoid risky controller changes.
What Are Typical Costs And Pricing Models?
Costs vary across three buckets, hardware, software, and services. Hardware includes sensors and edge compute, a one-time capex that scales with fidelity and site count. Software is often subscription-based, priced per asset, per edge node, or as a SaaS tier with cloud compute and model training included.
Professional services cover integration, labeling, and pilot tuning, often a significant one-time charge. Watch for hidden costs, like custom connectors, data egress, and ongoing model ops. Negotiate SLAs, clarify IP for models trained on your fleet, and compare total cost of ownership, not just license fees.
Which Metrics Should I Monitor First?
Start with metrics that map directly to dollars and risk. For equipment health, monitor uptime and unplanned downtime hours, mean time to repair, vibration RMS and spectral peaks for rotating assets, motor current harmonics for electrical systems, temperature deltas for thermal stress, and leak-detection signals for fluids and gases. Also track model-level KPIs, like precision at target recall and false alarm rate, plus adoption metrics such as percent of alerts acted on within SLA. Pick a small set, measure them rigorously, then expand.
How Do You Ensure Data Security?
Treat sensor data and models as sensitive assets. Segment OT and IT networks, use secure gateways with mutual TLS, and enforce least privilege for device identities. Encrypt telemetry in flight and at rest, apply signed firmware on edge nodes, and log provenance so every alert ties back to raw windows and model versions. Keep an on-prem or hybrid option if regulatory constraints require it, so data residency and operational control stay with the operator, and include clauses about model export and derivative rights in vendor contracts. Regularly run tabletop exercises that include simulated sensor spoofing and recovery.
What Skills Does My Team Need?
You need a blended skill set, not just data scientists. Signal engineers who understand vibration and electrical harmonics, reliability or maintenance SMEs, edge and cloud engineers for deployment and orchestration, and MLOps practitioners to version and monitor models.
Add a product-minded ops lead who bridges CMMS and workflows, and trainers who coach technicians to interpret model explanations. If those skills aren't available, partner with specialists or hire for domain-aware data engineering, because foundation models shift the work from pure model tuning to integrating physics-aware intelligence into operations.
What Future Trends Should I Watch?
Watch foundation models for physical signals. Just as language models transformed text, foundation models for Physical AI let teams transfer physical priors across assets without training from scratch, and Newton applies that approach directly to sensor data.
Expect more self-supervised learning on raw waveforms, tighter multimodal fusion across acoustics, vision, and electrical signals, and edge-native foundation inference for low-latency safety use cases. Regulation will push for stronger auditability and data provenance, and commoditization will surface new interoperability standards. Teams that build robust Physical AI infrastructure now will gain a sustained advantage.